1.1 Kommandovinduet
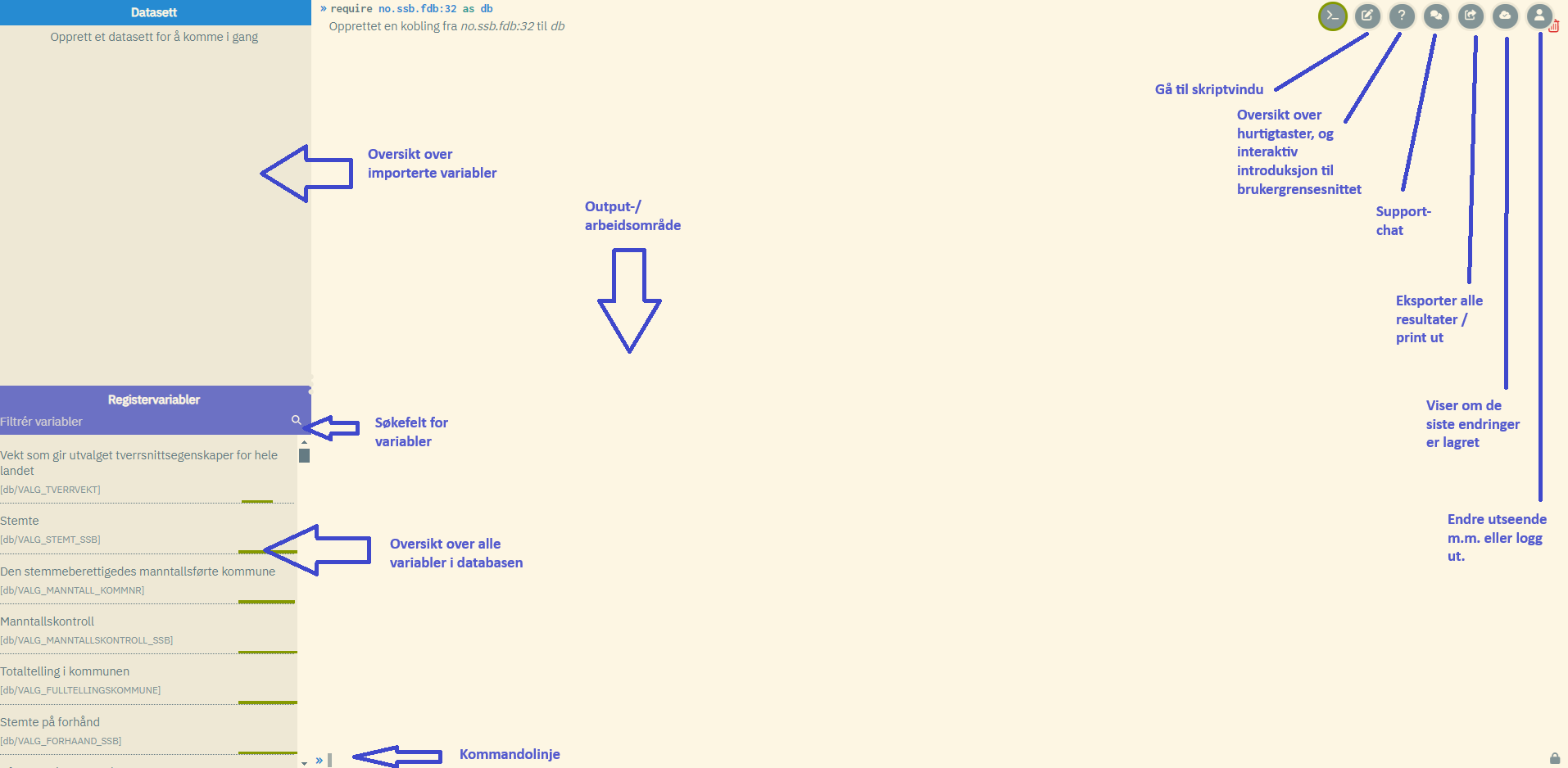
Kommandovinduet består av følgende:
- Arbeidsområdet (største feltet helt til høyre)
- Oversikt over tilgjengelige variabler (feltet nederst til venstre - feltet vil være blankt helt til en kobler seg mot databanken vha. kommandoen
require, jfr. kapittel 2.1) - Oversikt over variabler importert til egne datasett (feltet øverst til venstre)
- Kommandolinjen (nederst i arbeidsområdet)
Egne datasett bygges opp ved å importere, tilrettelegge og utvikle nye variabler basert på variabler fra datakatalogen. Datasett blir lagret i brukerens kommandovindu og forsvinner ikke uten at brukeren selv sletter dem. Se kapittel 2 for hvordan en oppretter datasett og importerer variabler.
Etter at kommandovinduet er blitt fylt opp med importerte variabler, kan det se slik ut:
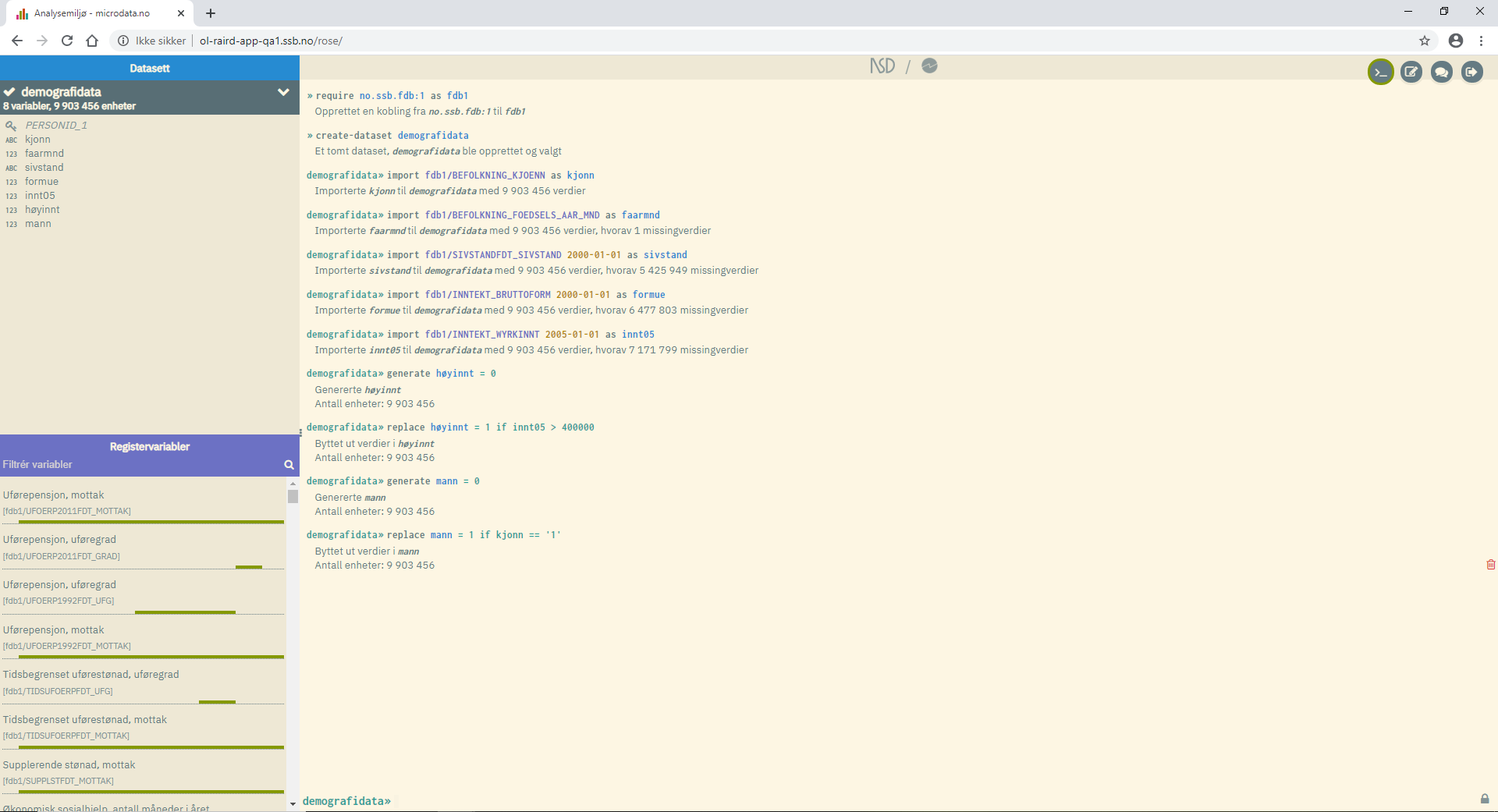
I eksempelet over er det opprettet et datasett med navnet "demografidata" som har 8 variabler og 9 903 456 enheter (individer). Blant variablene finnes identifikasjonsnøkkelen PERSONID_1. Dette er en systemvariabel som alltid følger med ved import av variabler. Den angir en unik personidentifikator som brukes som koblingsnøkkel. Systemet kobler automatisk sammen variabler ("left join") dersom en bare skal bruke data på personnivå, og da trenger en ikke forholde seg til denne variabelen1.
Arbeidsområdet viser en logg for hvilke kommandoer som har vært utført og hvilket svar man får, det være seg tabeller, figurer og annen feedback.
Helt nederst står det nå demografidata>> i stedet for >>, for å markere at en nå står i datasettet "demografidata". Om en oppretter
flere datasett vil vinduet øverst til venstre inneholde flere variabeloversikter tilsvarende den som gjelder for "demografidata". For
å arbeide på ulike datasett kan en skifte gjennom å bruke kommandoen use <datasett>. Da vil ledeteksten i kommandolinjen endre navn til det datasettet en har forflyttet seg til.
Footnotes
-
Identifikasjonsnøkkelen PERSONID_1 trenger bare angis eksplisitt i de tilfeller hvor en bruker kommandoen
collapsetil å aggregere opplysninger fra et sub-individnivå opp til individnivå. Et typisk eksempel er når en bruker kommandoenimport-eventtil å lage et datasett med "hendelser" som enhetstype (se kapittel 2.3.2). I praksis er dette datasett som kan inneholde flere verdimålinger per individ representert ved separate datarecords som peker til de ulike verdiene (en importerer alle verdimålinger mellom to tidspunkt for en gitt variabel), og som ikke uten videre kan kobles sammen med andre datasett. For å kunne koble sammen data basert på hendelsesopplysninger (import-event) med vanlige individnivå-datasett, må en bruke kommandoencollapsetil å aggregere dataene opp til individnivå og deretter bruke kommandoenmerge(se kapittel 2.8 og 3.4). Et annet eksempel på sub-individdata er såkalte kursvariabler (data om pågående studier) som kan inneholde flere verdimålinger per individ selv på tverrsnittsnivå (import), siden det er mulig å ta flere studier på samme tid. ↩